












【佳学基因检测】血友病基因检测项目
基因检测导读:
血友病 A 和 B 是由因子 (F) VIII 或 FIX 基因变异引起的。选择性收录可能会影响基因数据库中收录的变异分布。血友病致病基因鉴定基因解码将国际基于人群的儿科队列 (血友病基因检测数据库) 中的F8和F9变异谱与欧洲血友病和相关疾病协会 (EAHAD) 和疾病控制与预防中心血友病 A 或血友病 B 突变项目 (CHAMP/CHBMP) 数据库中发现的变异谱进行比较。在分析中,1941 名患者的遗传信息可用。52% 的重度血友病 A 患者存在内含子 22 倒位;在倒位阴性的重度血友病 A 患者中,最常见的变异是移码 (36%)、错义 (28%) 和无义 (20%)。重度血友病 B 中最常见的变异是错义 (48%)。在非重度疾病中,大多数变异是错义变异(中度血友病 A:91%;轻度血友病 A:95%,中度和轻度血友病 B:各 86%)。与数据库的比较表明,EAHAD 中与重度血友病 B 相关的错义变异比例 (68%) 高于血友病基因检测(48%) 和 CHBMP (46%)。血友病基因检测数据库人群队列为通过选择性收录收集数据的现有数据库提供了一种替代方案,因为它是一个维护良好的数据库,涵盖了所有致病F8和F9变异,并指示了受每种特定变异影响的患者数量。
血友病基因检测项目关键词
因子 VIII、因子 IX、血友病 A、血友病 B、遗传数据库、人群
血友病基因检测介绍
20 世纪 80 年代,编码人类凝血因子(凝血因子 F)VIII 和 FIX 的基因被发现,这使得血友病致病基因鉴定基因解码能够分别识别出血友病 A 和血友病 B 患者的致病变异。识别 FVIII/FIX 基因( F8/F9)中的致病变异对于确定女性携带者和产前诊断非常重要,并且有助于预测儿童血友病的严重程度。此外,变异类型已被证明容易导致抑制剂的发展。
测序技术的进步提高了变异的识别率,并促使人们创建数据库以增加对血友病遗传背景的了解。一般或中心突变数据库,如在线人类孟德尔遗传 (OMIM) 和人类基因突变数据库 (HGMD) 包含所有基因的变异列表。然而,这些中心数据库的管理员不一定是所有相关基因的专家。因此,这些数据库缺乏对特定疾病进行全面临床解释的重要特征。
另一方面,基于基因的数据库(即基因座特异性数据库 [LSDB])由对特定基因或表型具有科学专业知识的致病基因鉴定基因解码人员运行,并且是诊断和致病基因鉴定基因解码实验室的重要工具。第一个F8和F9的 LSDB于 20 世纪 90 年代初建立 。随后,基于网络的 LSDB 被创建,例如血友病 A 突变、结构和测试站点 (HAMSTeRS) 和 Hemobase。然而,缺乏可用时间和资金会对这些数据库的维护产生影响,如果不定期更新,数据库就会失去其相关性。此外,这些数据库并不总是易于访问。
因此,美国疾病控制与预防中心 (CDC) 以易于访问的格式编制了一个变异列表(CDC 血友病 A 突变项目 [CHAMP] 或血友病 B 突变项目 [CHBMP] 数据库),并且该列表每季度更新一次,包含最近发布的变异 。此外,欧洲血友病和相关疾病协会 ( EAHAD ) 在之前开发的数据库的基础上建立了一个项目,旨在收集涉及临床出血性疾病的单基因变异数据库,并为与止血相关的基因的 LSDB 提供单一门户网站。迄今为止,EAHAD 凝血因子变异数据库和 CHAMP/CHBMP 数据库中已经列出了 3000 多种导致血友病 A 的独特致病变异和 1200 多种导致血友病 B 的独特变异。这些数据库包含有关其他 LSDB 中先前收录的变异和文献中新发表的变异的信息。 EAHAD 凝血因子变异数据库还包括实验室直接提交的变异。然而,选择性收录可能会影响 CHAMP/CHBMP 和 EAHAD 数据库中收录的变异分布。此外,CHAMP/CHBMP 数据库中的数据以唯一变异列表的形式呈现,而不是由特定变异导致疾病的患者列表,而 EAHAD 数据库允许双向可视化数据。此外,作为血友病抑制剂致病基因鉴定基因解码的一部分,CDC 对 1400 多名血友病 A 患者和 220 多名血友病 B 患者进行了检测,并在单独的 Excel 文件(CHAMP/CHBMP 美国 [US] 文件)中收录了他们的变异结果。
PedNet(欧洲儿科血友病管理网络)登记处是一个基于人群的前瞻性登记处,其中包括 2000 年 1 月 1 日后出生、在参与中心之一接受诊断、治疗和随访的所有血友病儿童。在收集的所有变量中,包括F8/F9变体。
血友病致病基因鉴定基因解码描述了血友病基因检测数据库队列中致病性F8/F9变异的全部谱系,并比较了该基于人群的谱系与 EAHAD 和 CHAMP/CHBMP 已建立的参考数据库中发现的变异谱系的一致性。此外,血友病致病基因鉴定基因解码还表明血友病基因检测队列的数据可作为未曾接受过治疗的患者 (PUP) 致病基因鉴定基因解码的参考。
血友病基因检测大数据的收集
血友病基因检测数据库基于对 2000 年 1 月 1 日以后出生的患有血友病 A 或血友病 B 的 PUP 的临床、遗传和表型数据的前瞻性收集,并在http://ClinicalTrials.gov上注册,编号为NCT02979119。纳入的患者是在来自 18 个国家/地区(欧洲、加拿大 [2 个中心] 和以色列 [1 个中心])的 33 个合作血友病治疗中心之一确诊的。根据《赫尔辛基宣言》,每个中心都获得了伦理批准,并在纳入登记处之前获得了父母/看护人的书面知情同意。
血友病严重程度
在参与中心,至少两次测量 FVIII/FIX 水平,采用显色法或一步法测定,并确定血友病的严重程度。血友病基因检测数据库遵循国际血友病分类,将 FVIII/FIX 分为重度血友病 (FVIII/FIX <1%) 和中度血友病 (FVIII/FIX, 1%–5%) 。对于轻度血友病,仅纳入因子水平为 6%–25% 的患者。
基因分型和分类
基因分型由每个中心按照既定的常规在当地进行,检测倒位,主要使用桑格测序。近年来,一些中心已经使用了下一代测序。提供给协调中心的所有基因收录都根据人类基因组变异学会的建议进行了检查和修订。此外,所有基因变异均采用美国医学遗传学和基因组学学院和分子病理学协会 (ACMG/AMP) 的标准和术语进行分类。在大多数基因收录中,只收录了致病或可能致病的变异,但在某些情况下会收录第二种变异,例如多态性。在本文中,只使用导致血友病 A 或血友病 B 的致病变异。
与CHAMP/CHBMP和EAHAD已建立的数据库一致,PedNet数据库采用以下分类:-
F8 中的变异类型为内含子 22 倒位、内含子 1 倒位、替换、缺失、重复、插入、多态性或复杂变异。-
F9 中的变异类型分为替换、缺失、重复、插入、多态性或复杂变异。
F8和F9 中将分子后果 (变异效应) 分为错义、无义、移码、大或小 (> 或 <50 个碱基对) 缺失/插入/重复、沉默变异、剪接位点变异、启动子变异、内含子变异、多态性 (错义/剪接位点/沉默) 和倒位。
从血友病基因检测数据库提取数据
对于当前分析,数据提取于 2021 年 1 月 1 日进行,包括血友病类型、严重程度、性别、家族史、变异类型和分子后果的信息。没有已知血友病家族史的患者被视为散发病例。除内含子 1 或内含子 22 倒位外,具有变异效应的患者被视为倒位阴性患者。
从 EAHAD 数据库和 CHAMP/CHBMP US 文件中提取数据
为了进行比较,血友病致病基因鉴定基因解码收集了国际血友病数据库 EAHAD 和 CHAMP/CHBMP 中有关重症血友病的数据。在提取数据之前,血友病致病基因鉴定基因解码联系了 EAHAD 和 CHAMP/CHBMP 这两个注册中心,并允许使用公开数据。对于 CHAMP/CHBMP 注册中心,血友病致病基因鉴定基因解码使用了美国中心数据,因为这些数据是队列收集的数据,而国际数据库则包含每个发现的变体的数据。EAHAD 数据的提取日期为 2021 年 1 月 3 日。
血友病基因检测数据库致病基因鉴定基因解码人群和变异谱
在数据提取时,血友病基因检测数据库中包括 2278 名男孩和 19 名女孩。在本致病基因鉴定基因解码中,女性被排除在进一步分析之外。1941 名患者 (85%) 的F8或F9变异信息可用:86% (1631/1904) 的血友病 A 患者和 83% (310/374) 的血友病 B 患者。在疾病严重程度方面,分别对 92%、77% 和 78% 的重度、中度和轻度血友病 A 患者进行了基因分析,对 88%、84% 和 76% 的重度、中度和轻度血友病 B 患者进行了基因分析。35 名血友病 A 患者和 5 名血友病 B 患者 (分别为 2% 和 1%) 未发现致病变异。 84% 的具有已知家族史的血友病 A 患者 ( n = 898/1073 )、89% 的散发病例 ( n = 696/786 ) 和 82% 的无家族史患者 ( n = 37/45 ) 接受了基因检测。此外,80% 的具有已知家族史的血友病 B 患者 ( n = 187/234 )、88% 的散发病例 ( n = 116/132 ) 和 88% 的无家族史患者 ( n = 7/8 ) 接受了基因检测 。变异效应的分布如图所示表格1(针对血友病 A)和表 2(针对血友病 B)。
表1:患有血友病 A 的男孩在不同严重程度中变异效应的分布
| 错义突变 | 无义突变 | 沉默突变 | 剪接位点 | 启动子 | 移码突变 | 小型结构突变 (<50 bp) | 大型结构突变 (>50 bp) | 内含子 | 倒置 | 总计 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 严重 | 151 (13) | 110 (9.6) | 38 (3.3) | 1 (0.6) | 194 (16.9) | 3 (0.3) | 40 (3.5) | 614 (53.3) | 1151 | ||
| 中度 | 157 (91.3) | 1 (0.6) | 1 (0.6) | 6 (3.5) | 5 (2.9) | 1 (0.6) | 1 (0.6) | 172 | |||
| 温和 | 293 (95.1) | 1 (0.3) | 3 (1.0) | 3 (1.0) | 2 (0.6) | 4 (1.3) | 2 (0.6) | 308 | |||
| 总计 | 601 | 111 | 2 | 47 | 4 | 199 | 6 | 44 | 2 | 615 | 1631 |
表中仅显示具有已知变异的男性患者。数据以数字(百分比)的形式呈现。血友病基因检测数据库注册表中没有关于种族的详细信息。
表 2:患有血友病 B 的男孩在不同严重程度中变异效应的分布
| 错义突变 | 无义突变 | 沉默突变 | 剪接位点 | 启动子 | 移码突变 | 小型结构突变 (<50 bp) | 大型结构突变 (>50 bp) | 多态性 | 总计 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 严重 | 77 (48.1) | 34 (21.3) | 7 (4.4) | 7 (4.4) | 14 (8.8) | 3 (1.9) | 18 (11.3) | 160 | ||
| 中度 | 68 (86.1) | 1 (1.3) | 3 (3.8) | 4 (5.1) | 2 (2.5) | 1 (1.3) | 79 | |||
| 温和 | 61 (85.9) | 3 (4.2) | 6 (8.5) | 70 | ||||||
| 总计 | 206 | 35 | 13 | 17 | 16 | 3 | 18 | 1 | 309 |
表中仅显示具有已知变异的男性患者,数据以数字(百分比)形式呈现
血友病A 在 1170 名患有严重血友病 A 的患者中,1151 名(98%)被发现有致病变异。最常见的变异类型是内含子 22 倒位,在 1151 名患者中发现有 597 名(52%)。内含子 1 倒位发生在 17 名患者(1%)中。在非倒位患者(n = 537)中,变异效应包括 194 个移码(36%;主要影响外显子 14)、151 个错义(28%;主要影响外显子 23 和 26)、110 个无义(21%;主要影响外显子 14)和 38 个剪接位点变异(7%)、40 个大结构变化(7%)、3 个小结构变化(0.6%;在外显子 15、22 和 24 中)和 1 个启动子变异(0.2%)。19 名患者(2%)的致病变异仍然未知。
在患有中度( n = 172)和轻度(n = 308)血友病 A 的患者中 ,错义变异是最常见的变异效应,占中度病例的 157 例(91%)和轻度病例的 293 例(95%)。然而,尽管在中度血友病 A 患者中,这些变异几乎平均分布在 A1(19%)、A2(23%)、A3(21%)和 C1(21%)域之间,但在轻度血友病 A 患者中,它们最常位于 A2 域(40%)(图1A)。
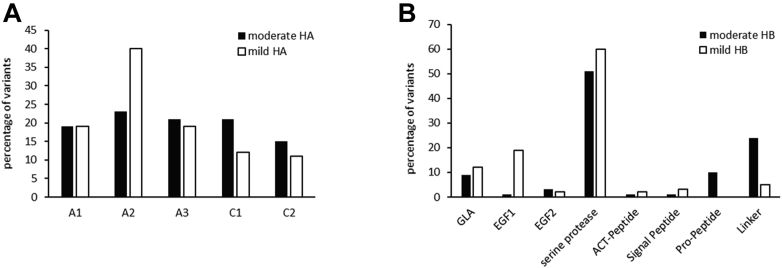
中度和轻度血友病中错义变异的位置。(A)根据中度或轻度血友病 A 中的因子 VIII 蛋白结构域进行定位;(B)根据中度或轻度血友病 B 中的因子 IX 蛋白结构进行定位。GLA:c-羧基谷氨酸结构域;EGF:表皮生长因子样结构域;ACT-Peptide:活化肽
血友病B 在重度血友病 B 患者 ( n = 160 ) 中,最常见的变异类型是致病点突变 ( n = 123;77%),根据变异效应分层时,血友病致病基因鉴定基因解码发现大多是错义变异 ( n = 77;48%) 和无义变异 ( n = 34;21%)。此外,还发现了大的结构变化 ( n = 18;11%)、移码变异 ( n = 14;9%)、启动子和剪接位点变异 ( n = 7;各 4%) 以及小的结构变化 ( n = 3;2%)。在一名患者中未发现致病变异。遗传变异遍布整个F9。
在中度 ( n = 79) 和轻度 ( n = 71) 血友病 B 中,错义变异在大多数患者中都代表了致病变异效应:68 例中度病例和 61 例轻度病例(各占 86%)。与血友病 A 一样,这些变异的分布在中度和轻度血友病 B 之间有所不同。两组中的大多数错义变异都发生在丝氨酸蛋白酶结构域中(中度血友病 B 为 51%,轻度血友病 B 为 60%)。然而,轻度血友病 B 与 EGF1 结构域中的变异更常见,而前肽或连接子中的变异则较少发现(图1B). 血友病B患者的重链和轻链之间错义变异的分布非常相似。
此外,据报道, F9启动子中的 16/17 (94%) 个变体与血友病 B 莱登表型有关。
根据家族史划分的血友病基因检测队列变异谱
血友病致病基因鉴定基因解码还比较了血友病基因检测队列中重度血友病散发病例和已知家族史病例的变异效应分布。重度血友病散发病例中的错义变异明显较少(61/614(10%),而已知家族史病例中为 87/515(17%);p=0.0007)。相比之下,根据家族史,重度血友病 B 患者的变异效应分布没有显著差异。
与 EAHAD 数据库和 CHAMP/CHBMP 文件比较的变异谱
在血友病致病基因鉴定基因解码致病基因鉴定基因解码的这一部分中,血友病致病基因鉴定基因解码将分析限制在患有严重血友病的患者身上。
血友病 A EAHAD 数据库未列出F8倒位。它包含 4691 名严重、倒位阴性的血友病 A 患者的分子信息。这些患者中最常见的变异效应是移码 ( n = 1487;32%)、错义 ( n = 1418;30%) 和无义变异 ( n = 966;21%),其次是剪接位点变异和大的结构变化。
美国队列包括 668 名患有严重血友病 A 的患者,其中 288 名 (43%) 有内含子 22 倒位,11 名 (2%) 有内含子 1 倒位;15 名患者 (2%) 未发现致病变异。在倒位阴性患者中,最主要的变异效应是移码 ( n = 108;31%)、错义 ( n = 100;28%) 和无义变异 ( n = 79;22%),其次是大的结构变化 ( n = 42;12%)。
对于血友病基因检测队列与 EAHAD 数据库和 CHAMP/CHBMP US 文件的比较,仅包括重度血友病 A 的倒置阴性患者。数据库中重度血友病 A 的倒置阴性患者的频谱几乎相同(图 2)。
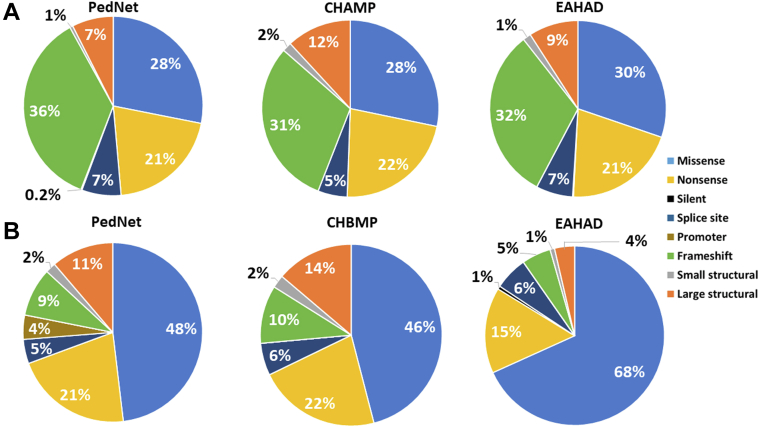
图 2:血友病基因检测数据库队列中的变异效应谱与 CHAMP/CHBMP 美国文件和 EAHAD 数据库的比较。 (A) 患有严重血友病 A 的反转阴性患者;(B) 重度血友病 B 患者。数据以百分比表示。
血友病B 在 EAHAD 数据库纳入的 3823 名严重血友病 B 患者中,错义变异(n = 2609;68%)是最常见的变异效应;在 592 名(15%)严重血友病 B 患者中,无义变异代表了致病变异效应。
在美国队列中,87 名严重血友病 B 患者中,错义变异(n = 40;46%)占变异效应的近一半,而 19 名患者(22%)出现无义变异。
将血友病基因检测队列与 EAHAD 和 CHBMP 数据库进行比较,错义变异是每个数据库中最普遍的变异效应(图 2)。
血友病基因检测数据总结
血友病致病基因鉴定基因解码收录了血友病基因检测数据库注册表中 1941 名患有血友病 A 或血友病 B 的人群队列中的F8/F9变异,并提出使用该数据库作为已建立的 LSDB 的替代方案。
首先,血友病致病基因鉴定基因解码发现 50% 的严重血友病 A 患者有内含子 22 倒位,而 CHAMP-US 队列中这一比例为 43%,普遍接受的患病率约为 45% 。然而,血友病基因检测数据库队列是第一个提供内含子 22 倒位患病率数据的大型人群队列,因此应被视为额外的基准。此外,在血友病基因检测队列和 EAHAD 数据库和 CHAMP-US 文件中,倒位阴性的严重血友病 A 患者的变异效应分布非常相似:移码、错义和无义变异是这些患者中最常见的变异效应。在严重血友病 B 患者中,错义变异最为常见,这一发现与其他数据库再次具有可比性。
接下来,血友病致病基因鉴定基因解码致病基因鉴定基因解码了非重度血友病患者中变异的分布情况。虽然错义变异是中度和轻度血友病患者中最常见的变异效应,但血友病致病基因鉴定基因解码发现它们的位置因疾病的严重程度而异。事实上,与轻度血友病 A 相关的错义变异最常位于 A2 域,而在中度病例中,这些错义变异更均匀地分布在 A1、A2、A3 和 C1 域之间。因此,轻度血友病 A 患者的重链受影响的可能性比中度血友病 A 患者更大。对于血友病 B,轻度血友病 B 中的变异在 EGF1 结构域中出现的频率高于中度血友病 B,但在前肽和连接子中出现的频率低于中度血友病 B。变异对 FVIII 或 FIX 蛋白结构的影响以及因此对疾病严重程度的影响是当前致病基因鉴定基因解码的课题,并且有证据表明,表型变异也可能与变异发生的区域有关。 然而,变异位置的作用值得进一步探索。
此外,在血友病致病基因鉴定基因解码 2% 的血友病 A 患者和 1% 的血友病 B 患者的相应基因中未鉴定出致病变异,这与 CHAMP 数据和一些收录相当,但与其他致病基因鉴定基因解码相比较低,其他致病基因鉴定基因解码未能在多达 11% 的患者中鉴定出致病变异。值得注意的是,基因检测的最新发展提高了变异检测能力,这可能解释了不同致病基因鉴定基因解码之间的差异。
此外,血友病致病基因鉴定基因解码还评估了严重血友病的变异谱是否因家族史而不同。有趣的是,错义变异在严重血友病 A 的散发病例中不太常见,而在严重血友病 B 患者中没有差异。致病基因鉴定基因解码的致病基因鉴定基因解码收录了血友病 B 患者的类似结果,但散发性和家族性病例谱的比较尚未得到广泛致病基因鉴定基因解码。请注意,血友病致病基因鉴定基因解码队列中散发病例的定义是基于家族中缺乏其他有症状/诊断的病例,而不是基于患者母亲的基因测试结果。重要的是,血友病 B 的单倍型分析表明,特别是在轻度疾病中,看似散发的病例可能在无人知晓的情况下存在相关性,这可能会影响血友病致病基因鉴定基因解码的观察结果。
最后,鉴于抑制剂的发展,拥有正确的变异谱框架来解释 PUP 致病基因鉴定基因解码结果(鉴于其代表血友病人群)极其重要。目前使用三种 LSDB:CHAMP(F8变异)、CHBMP(F9变异)和 EAHAD 凝血因子变异数据库(F8和F9变异)。这些数据库的发展大大提高了有关基因内变异位置、相关疾病严重程度和抑制剂发展风险的信息的可访问性。此外,这些数据库中描述的所有变异都符合人类基因组变异学会指南的通用命名法。然而,这些 LSDB 有一些局限性。首先,它们是从以前的 LSDB 或中央突变数据库开始构建的,并通过文献搜索或通过各个实验室或致病基因鉴定基因解码人员提交发现的变异进行补充和更新。因此,收录偏差会影响其准确性和完整性。其次,CHAMP/CHMBP 突变列表是变异的列表。由于它们没有表明由特定变异引起疾病的患者数量,因此无法基于这些数据将变异的频率推断为受该变异影响的患者的频率。事实上,CHAMP 突变列表只包括 2 个倒位列表(即内含子 1 倒位和内含子 22 倒位),尽管超过 40% 的严重血友病 A 病例是由倒位引起的。相反,在 CHAMP/CHBMP US 文件中,每一行都对应于基于人群的血友病抑制剂致病基因鉴定基因解码调查员中包括的一名患者。最后,F8倒位未在 EAHAD 数据库中列出。在这项致病基因鉴定基因解码中,血友病致病基因鉴定基因解码收录了多中心大型基于人群的血友病 A 或 B 型 PUP 队列中的全部F8/F9变异谱。因此,尽管数据库本身并非免费访问,但此处介绍的变异谱可以作为基于人群的参考,并且可能在未来的致病基因鉴定基因解码中有用。
血友病致病基因鉴定基因解码的致病基因鉴定基因解码有一些局限性。首先,血友病基因检测数据库仅收集 18 岁以下患者的数据。此外,轻度血友病且 FVIII 或 FIX 水平高于 25% 的患者未被纳入。因此,轻度血友病和/或不太严重表型的患者可能代表性不足,尤其是在没有已知家族史的情况下。然而,2001 年和 2014 年,国际血栓和止血学会科学和标准化委员会第 VIII 因子和第 IX 因子及罕见凝血障碍科学小组委员会建议,如果血浆 FVIII 或 FIX 水平在 5% 至 40% 之间,则将血友病归类为轻度。因此,EAHAD 凝血因子变异数据库和 CHAMP/CHBMP US 文件可能包括 FVIII 或 FIX 水平在 25% 至 40% 之间的轻度血友病患者,而血友病基因检测注册表则不包括。其次,血友病基因检测数据库注册表中包括一些患有血友病的女性,但她们很可能并不代表所有患有血友病的女性患者。因此,本致病基因鉴定基因解码未分析女性数据。此外,没有关于种族的详细信息,虽然血友病致病基因鉴定基因解码纳入了来自欧洲、加拿大和以色列的患者,但一些族群可能代表性不足。此外,血友病致病基因鉴定基因解码没有收录第二种变异。虽然 2 种致病变异可能很少见且临床意义仍未解决,但对于已知致病变异但表型不寻常的患者,以及在遗传咨询环境中,都应考虑它们。最后,有些患者尚未进行基因分析。重度血友病 A 和重度或中度血友病 B 患者接受检测的可能性更大,但有已知家族病史的重度血友病 A 患者接受基因检测的频率较低,这很可能是因为致病变异已经为人所知。然而,除非患者本人确认,否则血友病基因检测数据库不允许收录变异。这可能导致血友病致病基因鉴定基因解码的数据出现偏差。
总之,血友病基因检测数据库人群队列为通过选择性收录收集数据的现有数据库提供了一种替代方案,因为它是一个维护良好的数据库,涵盖了所有致病F8和F9变异,并指示了受每种特定变异影响的患者数量。
(如果您已经做了基因检测,想获取与基因检测型相对应的治疗方案,请点击此处上传您的基因检测结果)
(责任编辑:佳学基因)
